VanillaDB
Simple, fast, and extensible database system prototypes.
What's VanillaDB?
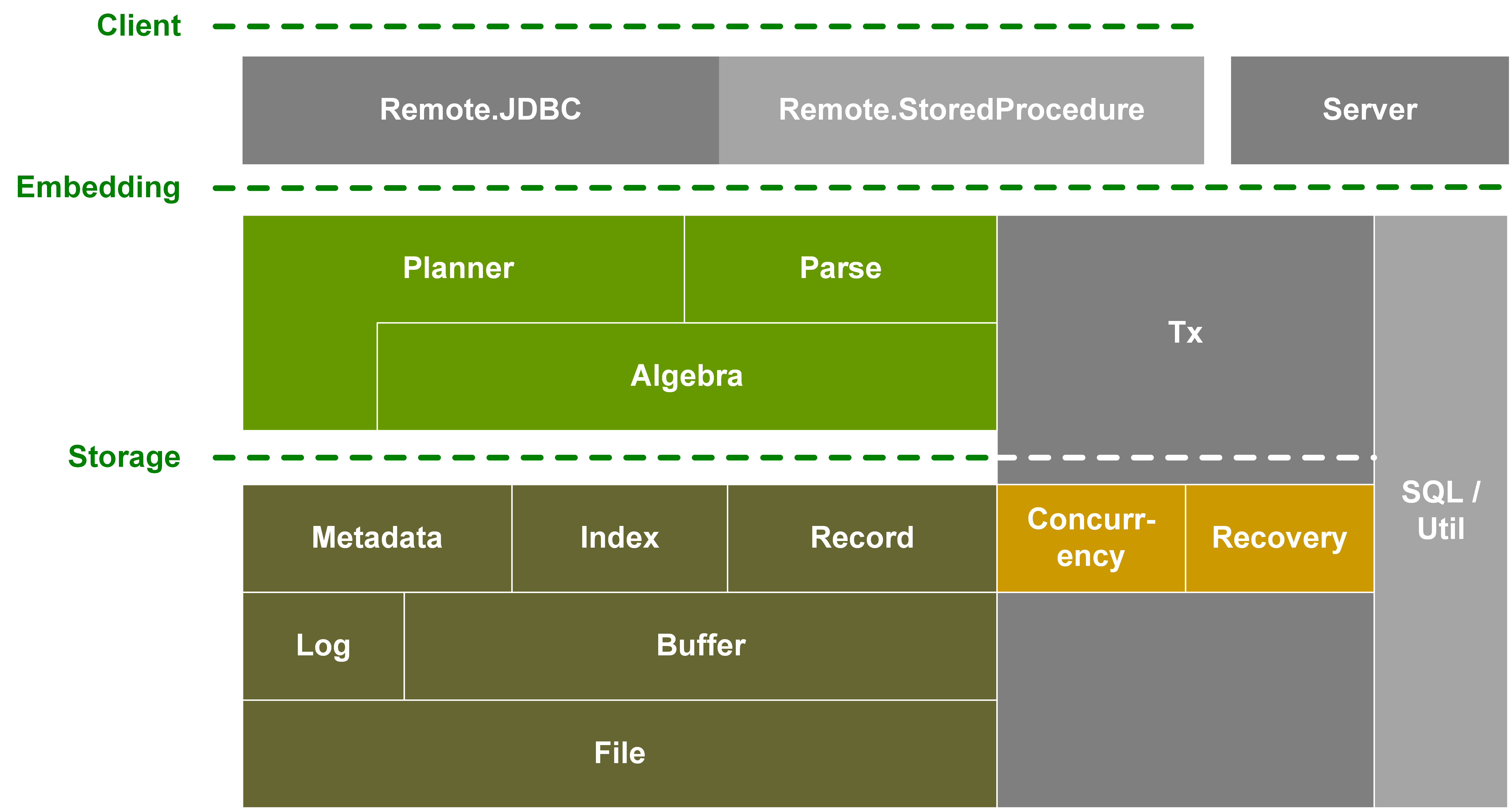
VanillaDB is a collection of simple-to-read, fast, and extensible database system components aiming to lower the barrier of new-system prototyping and/or learning the database internals.
Most relational database systems today are too complicated for practitioners, especially newcomers, to leverage and build creative systems/components upon. One main problem is that these systems have been optimized for decades, thus the source code is highly sophisticated and hard to understand. VanillaDB rewrites some key components of a distributed relational database system with the following goals in mind:
- Simplicity: clean code (written in Java), intuitive APIs, and well-documented internals even your grandma can understand;
- Performance: simple, but not the simplest, algorithms that deliver reasonable performance;
- Extensibility: modular architecture that eases the modification, enhancement/pruning, and development of new systems.
The source code of VanillaDB is released under the Apache 2.0 license. And we are happy to hear your feedback or feature requests at vanilladb@datalab.cs.nthu.edu.tw.
Target Audience
VanillaDB is ideal for:
- Database researchers who want to validate new algorithms on a real database system or to design a new system;
- Instructors who want their students to grasp solid knowledge about the internals of a database system and ability to make changes.
For instructors, we offer extra coding labs that help students get hands-on experience in some important modules (e.g., query planning, transaction processing, etc.). Please contact vanilladb@datalab.cs.nthu.edu.tw for more details.
VanillaDB has been used as a testbed in some research work (e.g., T-Part in Proc. of SIGMOD’16) and teaching materials in some DB courses (e.g., the “Cloud Database Systems” offered by National Tsing Hua University, Taiwan). It also serves as the core engine in some advanced systems (e.g., ElaSQL, a deterministic, distributed relational databases systems for OLTP workloads).
Sub-Projects
Currently, VanillaDB consists of two sub-projects, namely the VanillaCore and VanillaComm. The former is a single-node relational database engine and the latter provides the group communication primitives for distributed database systems.
Get VanillaCoreA new sub-project called VanillaBench is on the way.
Cite
To cite VanillaDB, please add the following to your BibTex:
@inproceedings{shwu2016tpart,
title={T-Part: Partitioning of Transactions for Forward-Pushing in Deterministic Database Systems},
author={Shan-Hung Wu and Tsai-Yu Feng and Meng-Kai Liao and Shao-Kan Pi and Yu-Shan Lin},
booktitle={Proceedings of the 2016 ACM SIGMOD International Conference on Management of Data (SIGMOD)},
year={2012},
organization={ACM}
}